前回は、機械学習(Deep Learning)に触れてみたところ、コンピュータに覚えさせる(学習させる)方法が重要ということで、色々弄っていました。
まずは文字認識をCRAFTというアルゴリズムを使って日本語を学習させています。
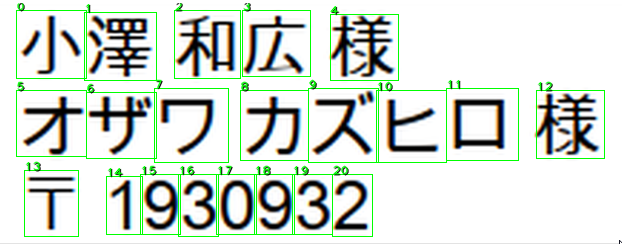
以下の画像は、パソコンの文字列を取ってきているので、認識率は高めです。1文字も狂いなく認識していることが分かります。まだ文字の意味までは分かっていません。あくまで文字という領域を把握したという程度です。
次は、実際のレシートを読み込ました。
斜めっているデータも学習させているため、認識は問題なさそう。
半角数字が特に弱い。「くら」はイメージ文字なので無視します。
この部分の精度が95%以上にならないと、次の工程の文字判別に影響するので学習の方法を変えないと駄目のようです。

次の画像は、字体が明朝になっていますが、字と字が密集しているところは結構間違った認識をしています。
こういうのも学習させないと誤った認識をするので、データ作成が重要になります。

拡大させてみましたが、それでも分からないようで、色々データを作ってみるしか無さそうです。

学習には丸1日以上掛かるため、進捗はどうしても遅くなってしまう点があります。
学習させている間、別PCにてユーザインターフェースの制作に取り掛かっているので、その進捗についても随時アップしていきます。