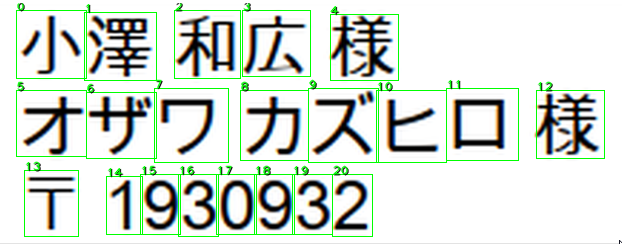
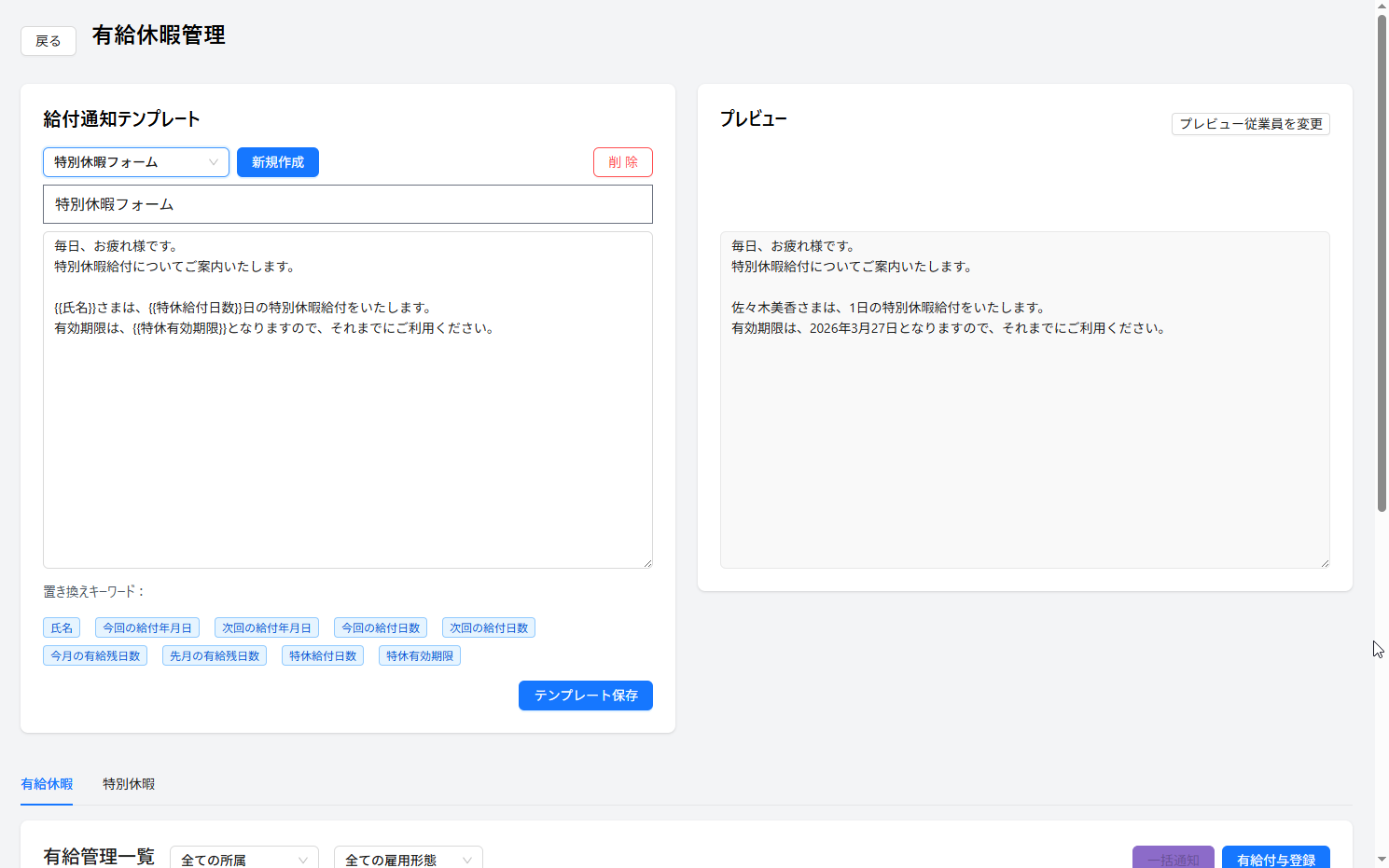
前回の結果をもとに、データセットを作り直したところ、改善したものと悪くなったものがありました。
以下のケースは、前回と比べて認識できていないところが改善しています。あと一歩です。
実際は、この後に各パーツ毎にトリミングを行い、再度推論を入れるため、精度は100%に近づくと思います。

以下についても前回と比べて改善している点と新たに読み取れてない部分が出てしまいました。
後処理のトリミングで拾えれば、このぐらいの認識率で問題なさそうです。

以下は悪くなってしまったケースです。前回のデータとは別のものを使ったからだと思うので、前回のデータも混ぜたデータセットで挑みます。